
Content scraping is an essential technique for businesses and developers looking to harness the vast information available online. By employing effective website scraping methods, users can extract valuable data from various sources, streamlining their research and analysis processes. Whether it’s for market research, competitive analysis, or content aggregation, web content scraping plays a pivotal role in gathering insights that drive informed decisions. With the right scraping tools, users can automate data extraction, saving time and resources while ensuring accuracy. As the digital landscape continues to expand, understanding the nuances of content scraping becomes increasingly important for those aiming to leverage online information.
The practice of data extraction, often referred to as web crawling or information harvesting, involves collecting data from websites for various purposes. Leveraging advanced scraping techniques, individuals and organizations can efficiently gather large volumes of information without manual intervention. This method not only enhances productivity but also opens up opportunities for deeper analysis and understanding of market trends. By utilizing appropriate scraping tools, users can navigate the complexities of online content, ensuring they remain competitive in a data-driven world. As the demand for reliable and timely information grows, mastering these data retrieval strategies is crucial.
Understanding Content Scraping and Its Implications
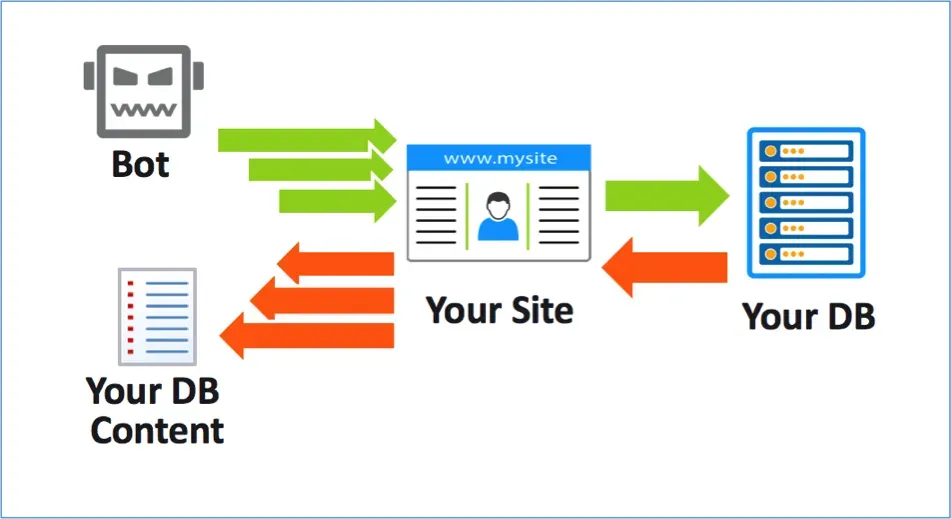
Content scraping refers to the automated process of extracting data from websites. This method often utilizes various tools and scripts to gather web content, which can include text, images, and other data types. While it can be useful for data analysis, market research, or aggregating information, it raises ethical concerns regarding copyright and the legality of using scraped content. Many websites, like nytimes.com, have strict policies against scraping, and violating these can lead to legal repercussions.
In addition to ethical considerations, content scraping can impact the performance of the target website. Excessive scraping can slow down server response times, disrupt user experience, and even lead to a website’s IP being blocked. For businesses and developers, it’s crucial to understand both the technical aspects of web content scraping and the legal framework governing it to avoid potential pitfalls.
The Role of Scraping Tools in Data Extraction
Scraping tools play a significant role in the data extraction process, allowing users to automate the gathering of information from various online sources. These tools can range from simple browser extensions to complex software solutions designed for extensive data harvesting. With the right scraping tool, users can efficiently collect large volumes of data, which can then be analyzed for various purposes, such as market research or competitive analysis. However, it is essential to choose tools that comply with the legal guidelines of the websites being scraped.
Many scraping tools come equipped with advanced features such as scheduling, data cleaning, and storage options, which make them invaluable for businesses that rely on real-time data updates. However, users should be cautious and ensure that their scraping activities do not violate the terms of service of the websites they target. By respecting these guidelines, businesses can avoid potential legal issues while still benefiting from valuable data extraction.
Legal Considerations in Web Content Scraping
When engaging in web content scraping, understanding the legal landscape is vital. Many websites include terms of service that explicitly prohibit scraping, and failing to adhere to these regulations can lead to legal action. Copyright laws also play a significant role, as the content on many sites is protected intellectual property. Therefore, it is crucial for individuals and organizations to familiarize themselves with the laws surrounding data extraction and ensure compliance to avoid potential lawsuits.
Moreover, some jurisdictions have specific laws governing data privacy and protection, which can further complicate scraping activities. Businesses should consider seeking legal advice to navigate these complexities effectively. By doing so, they can ensure their scraping practices align with legal requirements while still achieving their data goals.

Ethical Scraping Practices for Businesses
Adopting ethical scraping practices is essential for businesses that rely on data extraction from the web. This includes respecting the robots.txt file of websites, which indicates the areas of a site that are off-limits for scrapers. By adhering to these guidelines, businesses can maintain a positive relationship with data sources and reduce the risk of being blocked or facing legal challenges.
Additionally, businesses should consider the impact of their scraping activities on the target website’s performance. Implementing rate limiting and avoiding excessive requests can help minimize disruption to the website’s normal operations. Ethical scraping not only fosters goodwill but also enhances the sustainability of data extraction practices in the long run.
Best Practices for Effective Web Scraping
To ensure successful web scraping, adopting best practices is crucial. This includes selecting the right scraping tools that suit the specific needs of the project. Tools with user-friendly interfaces and robust features can significantly streamline the scraping process, making it easier to extract and analyze data. Additionally, users should ensure that their chosen tools are compatible with the websites they intend to scrape.
Another best practice is to continuously monitor the scraping process for any changes in the website’s structure. Websites often update their layout or content delivery methods, which can disrupt scraping efforts. By maintaining vigilance and adapting scraping strategies accordingly, businesses can ensure consistent and reliable data extraction.
The Future of Data Extraction and Web Scraping
The future of data extraction and web scraping is poised for significant evolution as technology continues to advance. With the rise of artificial intelligence and machine learning, scraping tools are becoming increasingly sophisticated, allowing for deeper insights and analysis of extracted data. These advancements are making it easier for businesses to gather actionable intelligence from web content, thereby enhancing decision-making processes.
However, as scraping technology evolves, so does the need for ethical considerations and legal compliance. Businesses must remain vigilant about adhering to regulations while leveraging new technologies. In the coming years, we can expect a more refined balance between the benefits of data extraction and the responsibilities that come with it.
Navigating the Technical Challenges of Web Scraping
Web scraping presents various technical challenges that can hinder data extraction efforts. One common issue is dealing with dynamic content generated by JavaScript, which can complicate the scraping process. To effectively scrape such content, users may need to employ advanced techniques or tools that can render the page as a browser would. This requires a deeper understanding of web technologies and may involve additional resources.
Moreover, anti-scraping mechanisms implemented by websites can pose significant obstacles. Techniques like CAPTCHA, IP blocking, and user-agent detection are commonly used to prevent automated scraping. To navigate these challenges, users must stay informed about the latest scraping technologies and strategies to bypass these barriers ethically and legally.
Utilizing APIs as an Alternative to Scraping
In some cases, leveraging APIs (Application Programming Interfaces) can serve as a more efficient alternative to traditional web scraping. Many websites offer APIs that allow for structured data access without the need for scraping. This can facilitate smoother data extraction processes while ensuring compliance with the website’s terms of service. By using APIs, businesses can gain access to regularly updated data and reduce the risk of legal complications associated with scraping.

However, it is essential to note that not all websites provide APIs, and some may limit the amount of data accessible through them. Therefore, businesses should assess their data needs and explore whether available APIs can meet these requirements before resorting to scraping. By prioritizing API utilization, organizations can engage in responsible data extraction practices.


The Impact of Web Content Scraping on SEO
Web content scraping can significantly impact SEO strategies, both positively and negatively. On the positive side, businesses can gather valuable insights into competitor strategies and market trends through scraping, which can inform their SEO efforts. Understanding what keywords competitors rank for or how they structure their content can provide a competitive edge.
Conversely, excessive scraping can lead to negative consequences, such as penalties from search engines for violating guidelines. Websites that are frequently scraped may experience slower loading times or even be flagged for suspicious activity, which can adversely affect their SEO ranking. Therefore, businesses should approach web scraping with caution and implement strategies that enhance their SEO without jeopardizing their website’s performance.
Frequently Asked Questions
What is content scraping and how does it work?
Content scraping refers to the process of automatically extracting data from websites. This can be done using various web scraping tools that simulate human browsing to collect information such as text, images, and other web content.
Is website scraping legal and ethical?
The legality and ethics of website scraping depend on the website’s terms of service. Some websites explicitly prohibit scraping, while others may allow it. Always check the site’s policy before engaging in data extraction.
What are the best scraping tools for web content scraping?
There are several popular scraping tools available for web content scraping, including Beautiful Soup, Scrapy, and Octoparse. These tools help automate data extraction processes, making it easier to gather information efficiently.
Can I use content scraping for competitive analysis?
Yes, content scraping can be used for competitive analysis by extracting data related to competitors’ products, prices, and marketing strategies. However, ensure that you adhere to legal guidelines and ethical standards when doing so.
What types of data can be extracted through web content scraping?
Web content scraping can extract various types of data, including text, images, product details, reviews, and pricing information from e-commerce sites, blogs, and news articles.

How can I prevent my website from being scraped?
To prevent content scraping, you can implement measures such as using robots.txt files to block crawlers, employing CAPTCHAs, and monitoring traffic for suspicious activities. Additionally, consider using anti-scraping tools to safeguard your content.
What are some common challenges in data extraction from websites?
Common challenges in data extraction include handling dynamic content loaded via JavaScript, dealing with anti-scraping measures, and ensuring data accuracy and relevance. It’s important to choose the right tool and techniques to overcome these obstacles.
Is it possible to scrape data from dynamic websites?
Yes, it is possible to scrape data from dynamic websites, but it often requires specialized tools that can render JavaScript content, such as Puppeteer or Selenium, which simulate a real user’s browser.
What is the difference between web scraping and data extraction?
Web scraping is a subset of data extraction that specifically refers to the process of collecting information from websites. Data extraction can encompass a broader range of techniques used to pull data from various sources, including databases and APIs.
Can I automate content scraping to collect data regularly?
Yes, you can automate content scraping by scheduling scraping tasks with tools like Cron jobs or built-in scheduling features in scraping software. This allows for regular data collection without manual intervention.
| Key Points |
|---|
| Content scraping refers to the automated extraction of information from websites. |
| The practice of scraping content can violate the terms of service of many websites, including news sites like nytimes.com. |
| It’s essential to respect copyright and intellectual property laws when considering content scraping. |
| There are legal alternatives for accessing news content, such as using APIs or subscription services. |
Summary
Content scraping refers to the extraction of information from websites, but it’s important to recognize that scraping content from sites like nytimes.com can often lead to legal issues. Many websites have terms of service that prohibit such actions, emphasizing the need to respect copyright and intellectual property laws. Moreover, there are legitimate alternatives available, such as APIs or subscription services, that allow access to content without violating any rules.



